
HackerRank: Merge the Tools! 笔记和题解
HackerRank: Merge the Tools! 笔记和题解。重新写了一些问题的描述,写了四种不同的解法,图片均为原创。
Table of Contents
背景
这篇笔记是我在做 HackerRank 上的一道 Python 题目时写下的,题目叫做 Merge the Tools!。这道题在 HackerRank 上是 Medium 难度,但它的描述写得好复杂,其实想要实现的东西是蛮简单的。
问题描述
为了方便大家理解这个问题,我会在这里重写一下它的问题描述,并引入一个原题没有的变量 $m$($m$ 为整数)帮助解释。
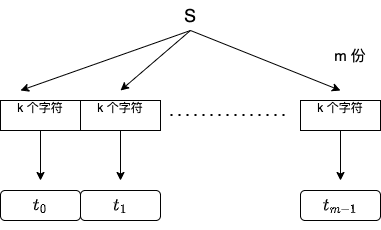
首先是给定一个 string $s$(长度为 $n$),我们将其分成 $m$ 个 substrings(子字符串),每一个 substring 我们将其称为 $t_{i}$,每个 $t_{i}$ 有 $k$ 个字符。
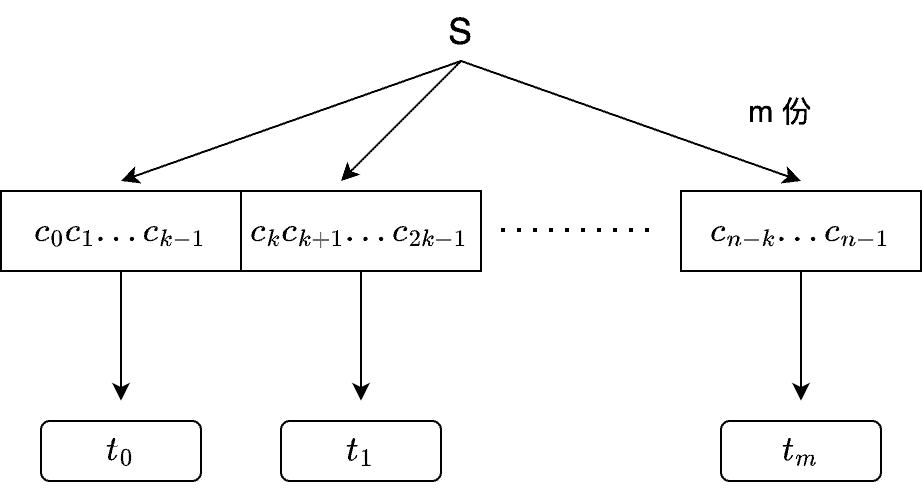
每个字符我们称其为 $c_{i}$,$s$ 总共有 $n$ 个字符:
接着我们需要用 $t_{i}$ 创造 $u_{i}$,并满足两个条件:
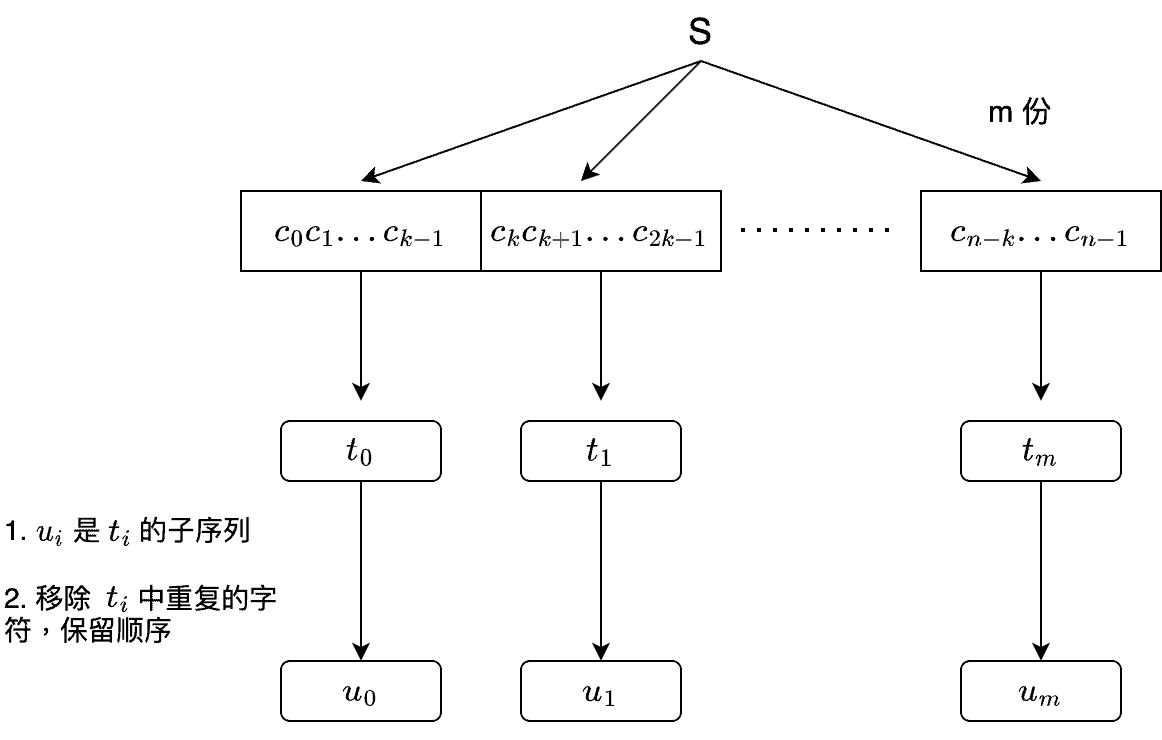
$u_{i}$ 需要满足两个条件:
- $u_{i}$ 是 $t_{i}$ 的 subsequence (子序列)
- 移除 $t_{i}$ 中重复的字符,并保留顺序
题目会给定 $S$ 和 $k$,要求输出每一个 $u_{i}$,也就是 $u_{0}$ 到 $u_{m}$。题目中也限定了 $k$ 为 $n$ 的因数,也就是确保了 $m$ 为整数。
这道题的解释之所以会那么难看懂,就在于它的描述都是基于 $S$ 和 $k$ 的,而其实它就是在说将一个 string $S$ 给分成 $m$ 等分个 substrings,每个 substring 为 $k$ 个字符,也就是 $n = k \times m$,再将每个 substring 在保留顺序的同时去除重复的字符。
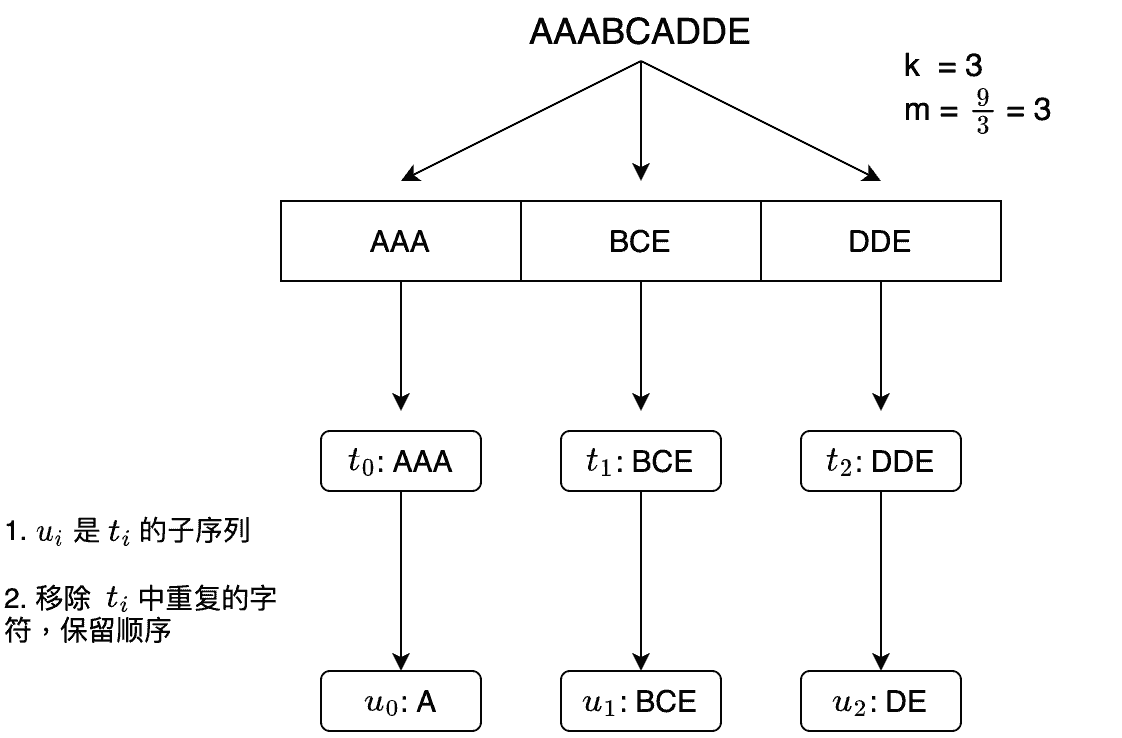
举例,假设 s = "AAABCADDE",k = 3
分析
在读懂题意后,解决问题的关键就在于:给定一个 string $t_{i}$,如何在保留顺序的情况下,移除重复的字符。下面我会给出四种不同的解法。
(注意:这里的第一和第二种方法,要求使用的 Python 版本在 3.7 或以上)
解法
第一种:用 Python 的 dictionary 做 Hashing
基本思想就是,我们想要用 Python 的 dictionary 来做一个 Hashing 的效果。
def merge_the_tools(string,k):
n = len(string)
m = int(n/k)
for i in range(0,n,k):
d = {key:0 for key in string[i:i+k]}
print("".join(d))这里设置 value 为 0 是因为我们打印的时候只需要用到 dictionary 的 keys。
第二种: 用 Python 的 dict.fromkeys() method
第二种方法和第一种方法基本一样,不过我们使用 dict.fromkeys() 来创建 dictionary。
dict.fromkeys(keys,values) 用法
dict.fromkeys() 可以用来创建一个新的 dictionary,可以传入两个参数,第一个参数是必须的,需要传入一个 iterable,作为 dictionary 的 keys。第二个参数是 optional,可以传入一个指定的 value 作为所有 keys 的值,如果不传入则默认为 None。
比如:
a = "ABC"
b = 0
print(dict.fromkeys(a,b))
# 输出:{'A': 0, 'B': 0, 'C': 0}或者:
a = "ABC"
b = [1,2,3]
print(dict.fromkeys(a,b))
# 输出:{'A': [1, 2, 3], 'B': [1, 2, 3], 'C': [1, 2, 3]}注意这里,即使第二个参数传入 iterable,它也会给每一个 key 设置同样的 value,而不是与 keys 一一对应起来。
解法
def merge_the_tools(string, k):
n = len(string)
m = int(n/k)
result = []
for i in range(0,n,k):
result.append("".join(dict.fromkeys(string[i:i+k])))
print("\n".join(result))第三种:用 Python 的 OrderedDict
第一和第二种解法只适用于 Python 3.7 以上的版本,因为 Python 在 3.7.0 之后,dictionary 才改为 insertion-order preserved,也就是创建时会保留原本的顺序。
在 3.7.0 之前的版本,如果你想要确保创建 dictionary 时可以保留原本的顺序,需要使用 OrderedDict:
from collections import OrderedDict
def merge_the_tools(string,k):
n = len(string)
m = int(n/k)
result = []
for i in range(0,n,k):
result.append("".join(OrderedDict.fromkeys(string[i:i+k])))
print("\n".join(result))第四种:利用 List Comprehension
第四种是我一直在想,能不能用 list comprehension 一行搞定时想到的,我觉得挺有趣,虽然有点取巧,但我上网搜了搜,发现的确有人会这样写,就还是分享出来了哈哈。
def merge_the_tools(string,k):
n = len(string)
m = int(n/k)
for i in range(0,n,k):
result = []
[result.append(x) for x in string[i:i+k] if x not in result]
print("".join(result))主要就是倒数第二行,在给 result append x 的时候,同时也用 result 做条件。而如果你把倒数第二行打印出来,会得到这样的结果:
# 假设 S = AAABCADDE,k = 3
def merge_the_tools3(string,k):
n = len(string)
m = int(n/k)
for i in range(0,n,k):
result = []
print([result.append(x) for x in string[i:i+k] if x not in result])
# print("".join(result))输出:
[None]
[None, None, None]
[None, None]这是因为 append() 会 return None,而倒数第二行整体会 return 一个 list。
参考

然的博客 Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}